语法杂记
语言细节
POD类型
POD(Plain Old Data,简单旧数据)是C++中的一个概念,它指的是一种可以通过简单内存复制进行复制和传输的数据类型。POD类型的对象可以通过memcpy或其他等价的操作进行复制,而且它们的内存布局是完全透明和可预测的。
对我来说,POD类型有如下作用:
- 可非常简单地进行序列化反序列化。
- 拷贝性能好。可以简单使用内存拷贝来复制对象。
- 支持作为原子变量。
std::Atomic
内存顺序(Memory Order)
关于原子变量的内存顺序非常非常之复杂,本文无意展开。六种内存顺序的解释及示例请参考下面的文章,写得非常生动详细且环环相扣:
本文讨论一些重要的部分。
memory_order_relaxed
这种内存模式是最宽松的内存模式,他除了保证操作是原子操作之外什么都不会保证。 举例来说,下面的线程1是设置了x和y的参数
std::atomic<bool> x{false}, y{false};
void thread1() {
x.store(true, std::memory_order_relaxed); // (1)
y.store(true, std::memory_order_relaxed); // (2)
}
void thread2() {
while (!y.load(std::memory_order_relaxed)); // (3)
assert(x.load()); // (4)
}
当我们谈论到除了原子操作之外什么都不会保证时,这意味着这两个操作是可被重排序的,也就是说x和y的CPU执行顺序无法被保证,也有可能先执行y.store再执行x.store。 因此thread2中的断言有可能会失败。
现代CPU为了让流水线的并行度增大,会支持指令乱序执行/重排序,以减少流水线气泡。相同代码在不同CPU核心的重排序后的执行顺序可能会不同,因此会造成上述问题。
事实上除开CPU的重排序外,编译器也有可能对指令进行重排序。可参考此文章乱序执行的那些事儿
注意,如果上述代码改成如下代码则不会出现断言失败问题:
std::atomic<bool> x{false}, y{false};
void thread1() {
x.store(true, std::memory_order_relaxed); // (1)
y.store(true, std::memory_order_release); // (2)
}
void thread2() {
while (!y.load(std::memory_order_acquire)); // (3)
assert(x.load()); // (4)
}
为什么会出现这种情况呢?因为memory_order_release会保证当前线程没有读写指令会被重排序到此条指令之后,因此x.store并不会在y.store之后执行;同样,memory_order_acquire会保证当前线程没有读写指令会被重排序到当前指令之前。
引用计数一例
这一节我们举一个引用计数器的例子: 我们想要实现一个对象的引用计数器,使其能够在多线程情况下计数永远安全。我们聚焦于计数器自增操作:
inline T conditional_increment() {
while (true) {
T c = value.load(std::memory_order_acquire);
if (c == 0) {
return 0;
}
if (value.compare_exchange_weak(c, c + 1, std::memory_order_acq_rel)) {
return c + 1;
}
}
}
我们想象有两个线程同时想要进行自增操作,引用计数初始值为1:
| 步骤 | 线程A | 线程B | 内存值 |
|---|---|---|---|
| 1 | c = load() → c=1 |
1 | |
| 2 | c = load() → c=1 |
1 | |
| 3 | compare_exchange(c=1, new=2) |
1→2 ✅ | |
| 4 | 返回 2 | 2 | |
| 5 | compare_exchange(c=1, new=2)❌ 失败(内存=2 ≠ c=1) |
1 | |
| 6 | c 被更新为内存值 2 | 2 | |
| 7 | 循环重试:c=2 | 2 | |
| 8 | compare_exchange(c=2, new=3) → ✅ |
2→3 | |
| 9 | 返回 3 | 3 |
在步骤5时,线程B尝试对c进行自增,但是通过原子操作compare_exchange发现线程B中的c值与内存中的c值不一致,因此会立即自旋,进入下一次循环。在步骤8进入下一个循环时此时总算与内存值一致,因此可以成功修改引用计数。
上述步骤中,至关重要的就是这个compare_exchange函数,此函数在x86平台上汇编指令为
mov eax, 1 ; 期望值 c=1
mov ebx, 2 ; 新值 c+1=2
lock cmpxchg [c_addr], ebx
首先,cmpxchg是x86上的一个指令,在寄存器(eax)的值与c的值相同时,会将exb的值与eax的值进行交换。重要的一点在于,这个指令实际上干了比较和交换两件事,但是却只需要一条指令,因此不可被打断。
其次,compxchg前还有一个lock前缀,这个前缀表示当前指令会“占有”内存总线(如果缓存未跨行则会占有缓存行(Cache Line))。假设线程A已经锁定了内存总线,此时线程B想要执行相同的指令,那么线程B会被阻塞在流水线解码阶段,等待A执行完毕解锁总线后再继续执行。
上述两点共同保证了compare_exchange指令只能够在缓存一致的情况下顺序执行。
mutable关键字
mutable是C++中的关键词,用于去掉const修饰符的作用。
当写了一个数据的接口如下时,get()函数表现为const,但是实际上会使用到一个读锁,因此需要让读锁打破const限制符。
template<typename T>
class Data{
mutable read_lock;
T data;
public:
Data() = default;
const T& get() const;
void set(const T&);
}
template<typename T>
const T& Data<T>::get() const{
read_lock.lock();
const T& tmp_data = std::move(data);
read_lock.release();
return tmp_data;
}
likely和unlikely
对于一个分支,用于告诉CPU更倾向于走/不走这一分支。
在C++20以前,这俩都是一个宏,用法如下:
if(likely(size==0)){
...
}
else{
...
}
而C++20及之后,这俩提拔为了属性关键字。用法如下
if(size==0) [[likely]]{
...
}
else{
...
}
从汇编来看,仅仅是把更可能的部分的跳转标签写到离跳转语句更近的地方而已。
模板
准备好了吗,前面可是地狱哦。
基础概念
本文大量引用此文章真正意义上的理解 C++ 模板。 模板的最基本用法就是用于生成代码,让同一个函数、类型等能够自动支持不同类型的参数。如下所示,模板函数add将相加的两个操作数的类型作为模板,因此可以自动生成多种类型的相加函数。
template <typename T>
T add(T a, T b) {
return a + b;
}
template int add<>(int, int); // 显式实例化
int main() {
Pos2D pos0 = {0, 1}; // 假设存在一个储存2D位置信息的结构,其重载了加号操作符
Pos2D pos1 = {-1, 1};
add(1, 2); // 自动推导、隐式实例化
add(pos0, pos1); // 自动推导、隐式实例化
add<float>(1, 2); // 显式实例化
}
参数包
编程技巧
内存分配
placement_new
普通的new是一个内存申请+构造对象的过程,而申请内存是一个比较耗时的过程,而placement_new是在已申请的内存中构造对象的过程,非常常用在内存池中!
池分配器
在存在大量对象的系统中,如果每个对象都使用new,会造成如下问题:
- 分配内存时可能会进行系统调用。
- 分配的内存可能不连续,会导致缓存命中率下降。
- 分配的内存可能不连续,产生内存碎片。 池分配器会一次性分配一大块连续的内存,而后在需要创建对象时,直接使用placement_new进行对象构造。 Godot的池分配器算法非常精妙,释放和申请内存都只需要O(1)复杂度,唯一缺点在于其额外储存了一份空闲位置的指针数组,其数量为池的容量。(暂时没有精力梳理成笔记)
写时复制(Copy on Write)
写时复制是指:
- 读取时共享:多个对象共享同一块内存
- 写入时分离:当需要修改数据时fork一份内存再做修改 Godot引擎的实现方法是通过对一块数据添加引用计数,记录有多少个对象引用了同一块内存。如果引用计数为0则会删除内存。当发生写事件时,会判断引用计数,若引用计数为1则说明只有自己引用,因此无需有其他操作;若引用计数大于1,则会拷贝对象再执行写操作。
Godot还进行了一些拷贝时的优化,其会判断该对象的类是否属于可平凡拷贝类,若为可平凡拷贝类则说明可以直接拷贝内存进行拷贝,否则需要使用拷贝构造进行开销稍大一些的拷贝。
// 对于平凡可复制的类型
if constexpr (std::is_trivially_copyable_v<T>) {
memcpy((uint8_t *)_ptr, (uint8_t *)prev_data._ptr,
copied_element_count * sizeof(T));
} else {
// 对于复杂类型,需要调用复制构造函数
for (USize i = 0; i < copied_element_count; i++) {
memnew_placement(&_ptr[i], T(prev_data._ptr[i]));
}
}
而虚幻引擎的COW特别是字符串的COW更甚,他除了写时复制外,还会把字符串内容进行全局索引,全局去重更加高效。
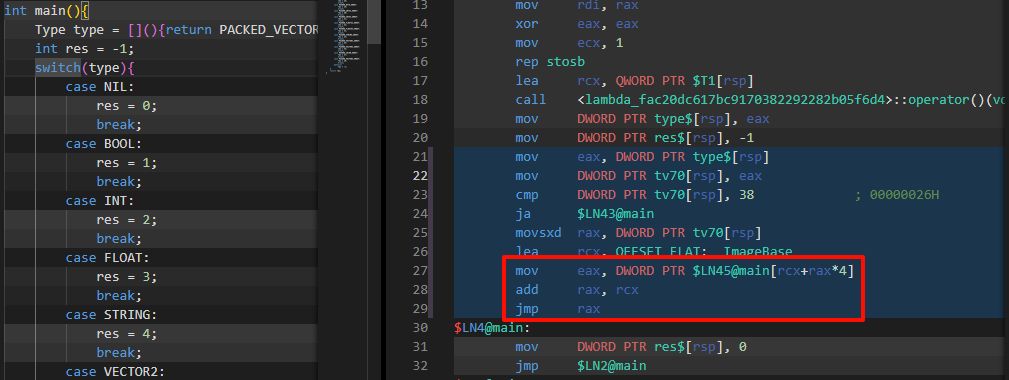
Switch性能
这里的switch性能并不是想要探讨Nintendo Switch的CPU性能和GPU性能。
这个故事要从一段代码说起。Godot引擎中,其最基础的数据类型Variant的转化为字符串的代码如下:
class Variant{
...
enum Type {
NIL,
BOOL,
INT,
FLOAT,
STRING,
...
}
...
}
String Variant::stringify(int recursion_count) const {
switch (type) {
case NIL:
return "<null>";
case BOOL:
return _data._bool ? "true" : "false";
case INT:
return itos(_data._int);
case FLOAT:
return String::num_real(_data._float, true);
case STRING:
return *reinterpret_cast<const String *>(_data._mem);
...
}
}
其执行方式竟然是通过"低效"的switch进行逐行判断。作为一个性能要求非常高的游戏引擎,为什么不用跳转表的方式进行实现。仔细查阅资料后,发现对于switch条件数量较多、参数为整数且条件比较连续的情况下,编译器正是会倾向于编译为跳转表的实现!顺带一提,Lua解释器也是使用显式的跳转表以加速指令翻译速度。
经简单测试,x86 Clang在分支较少的情况下也会使用跳转表,而x86 MSVC则会在分支较多才会进行跳转优化。
Open: Pasted image 20250806000427.png
 此外,在分支条件很多且值很分散的情况下还会优化为二分查找。可参考下面的文章
此外,在分支条件很多且值很分散的情况下还会优化为二分查找。可参考下面的文章